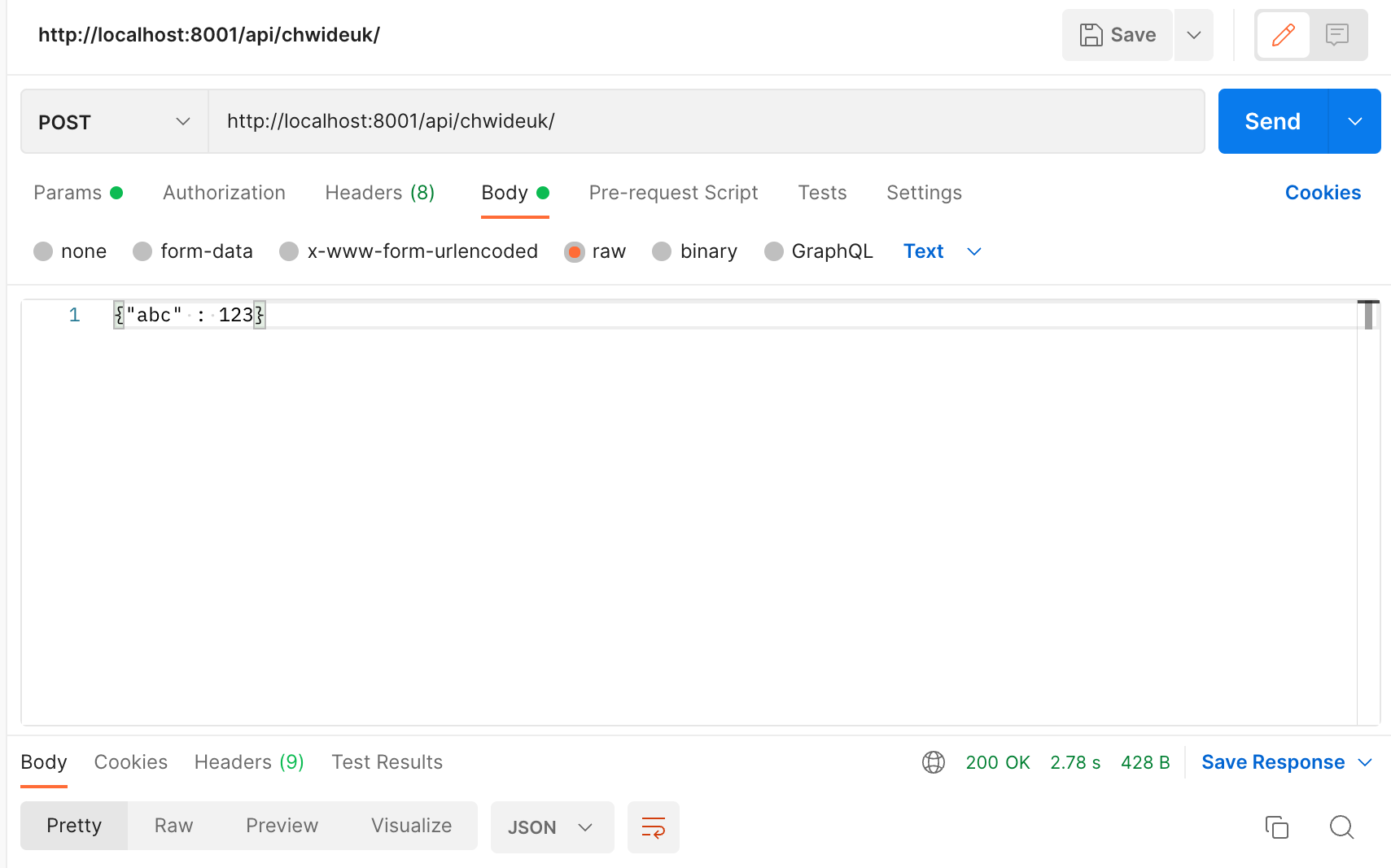
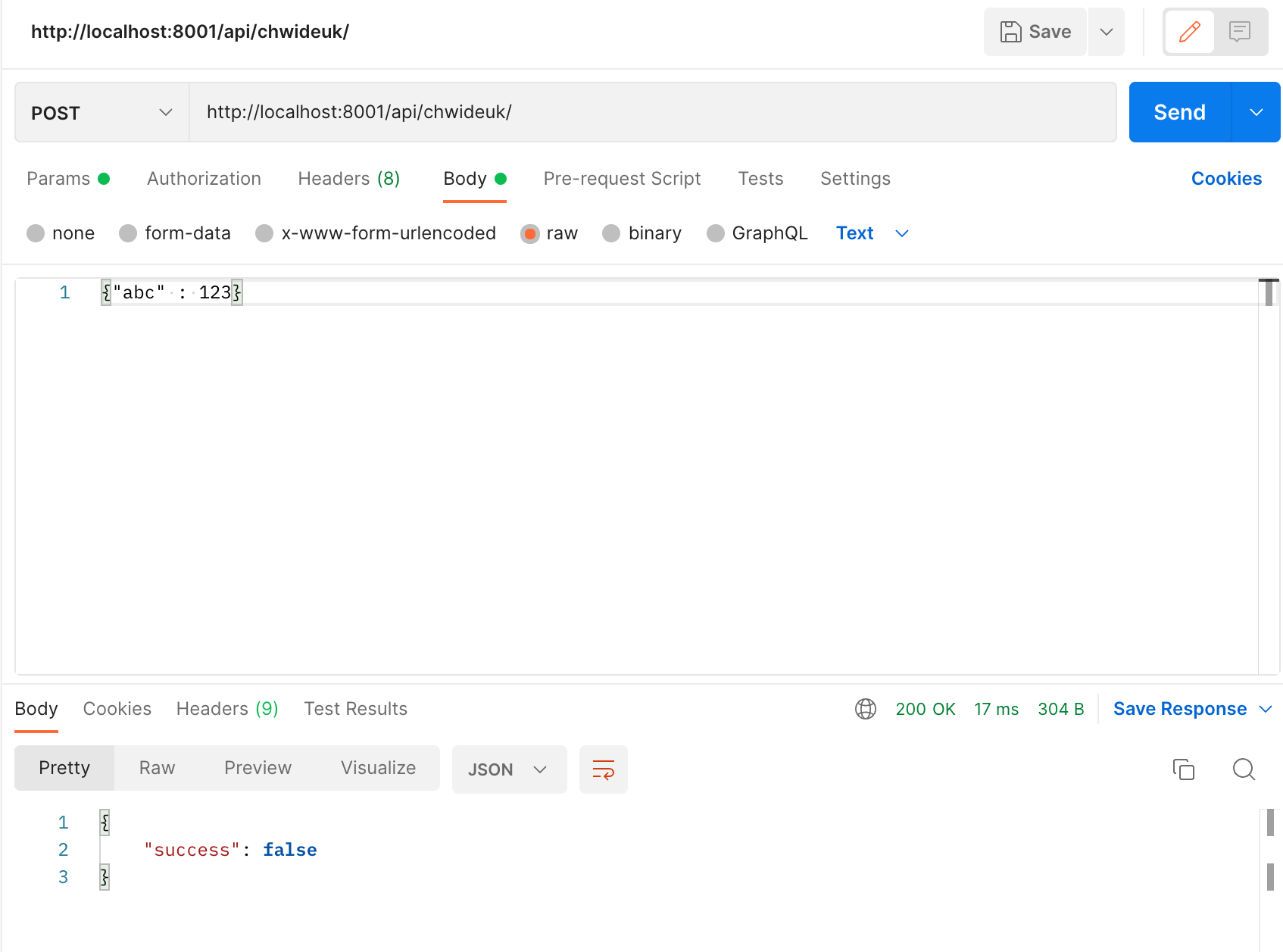
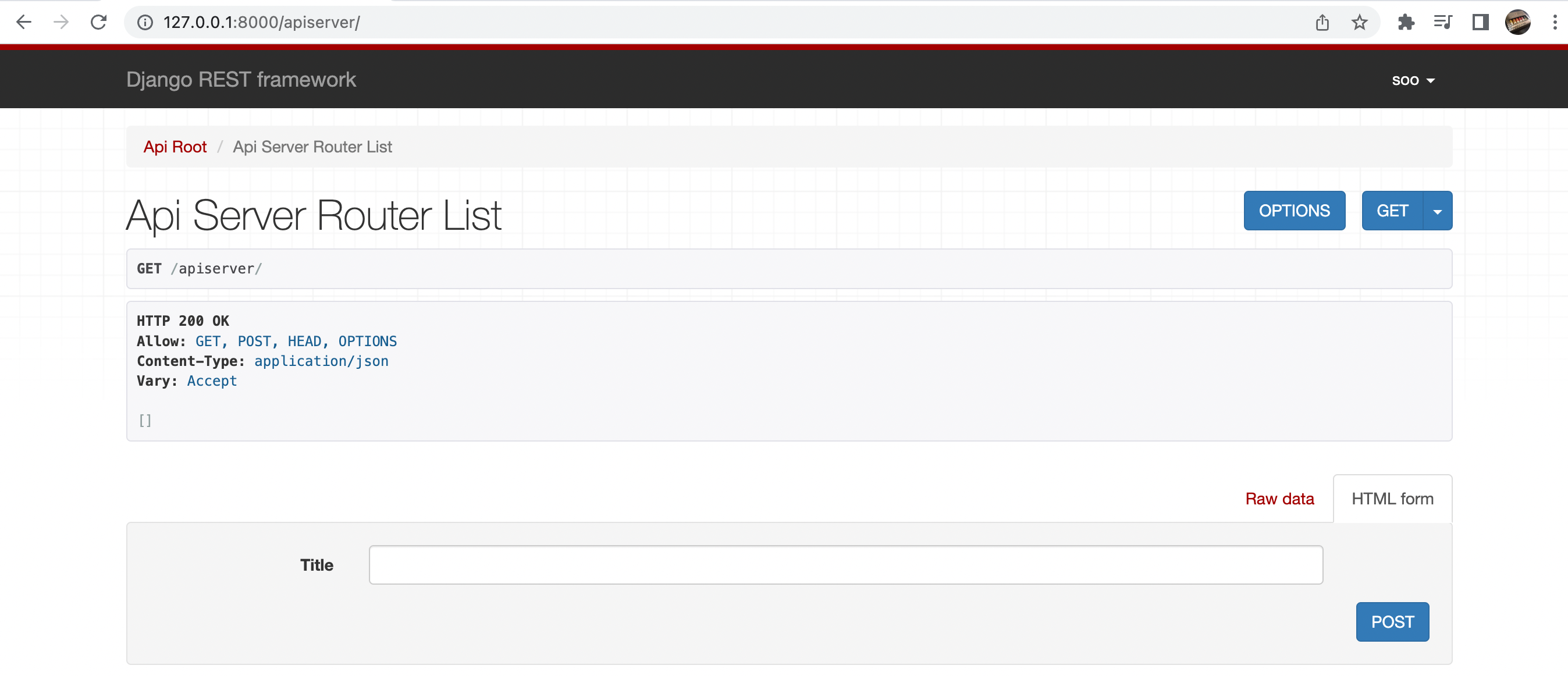
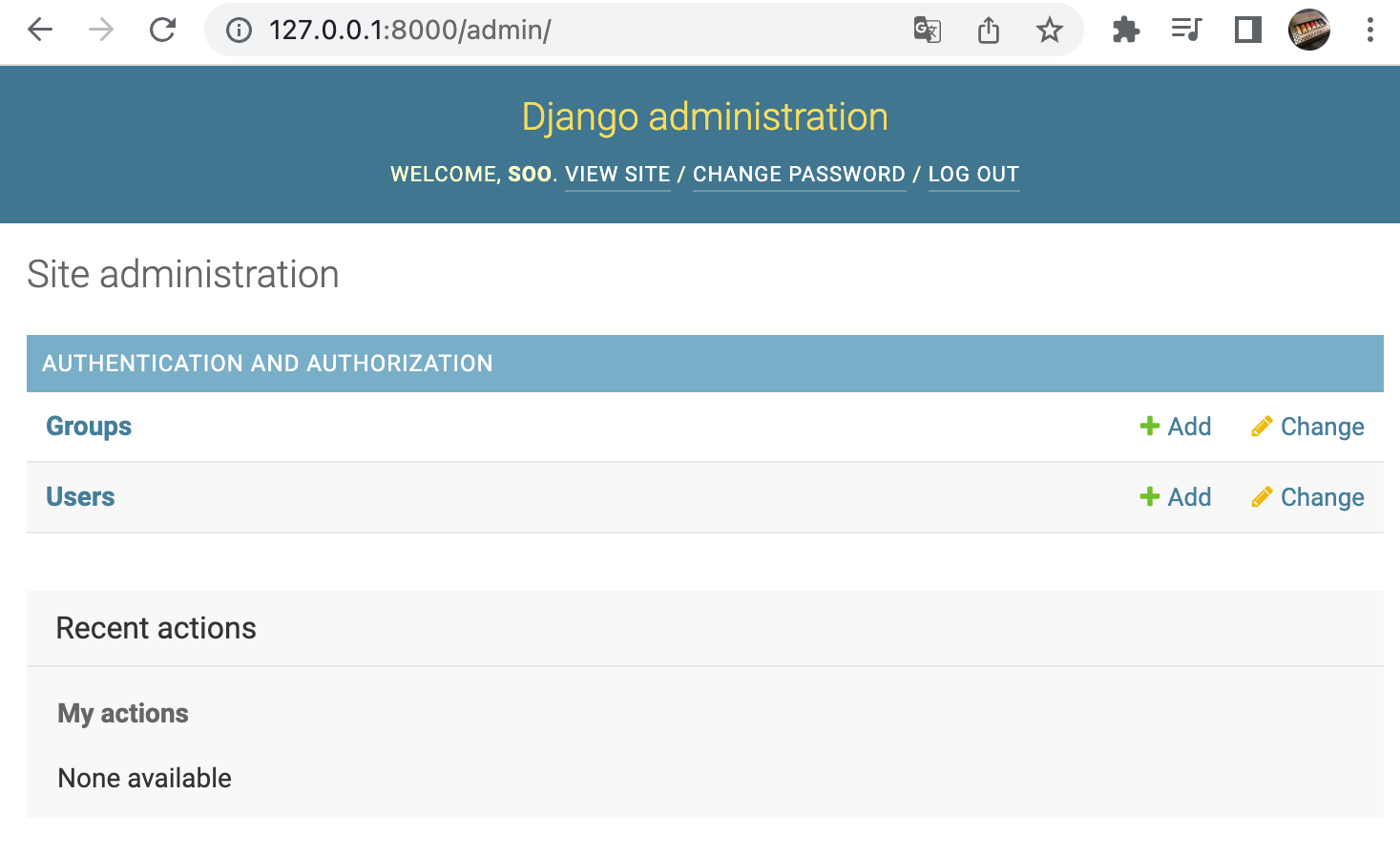
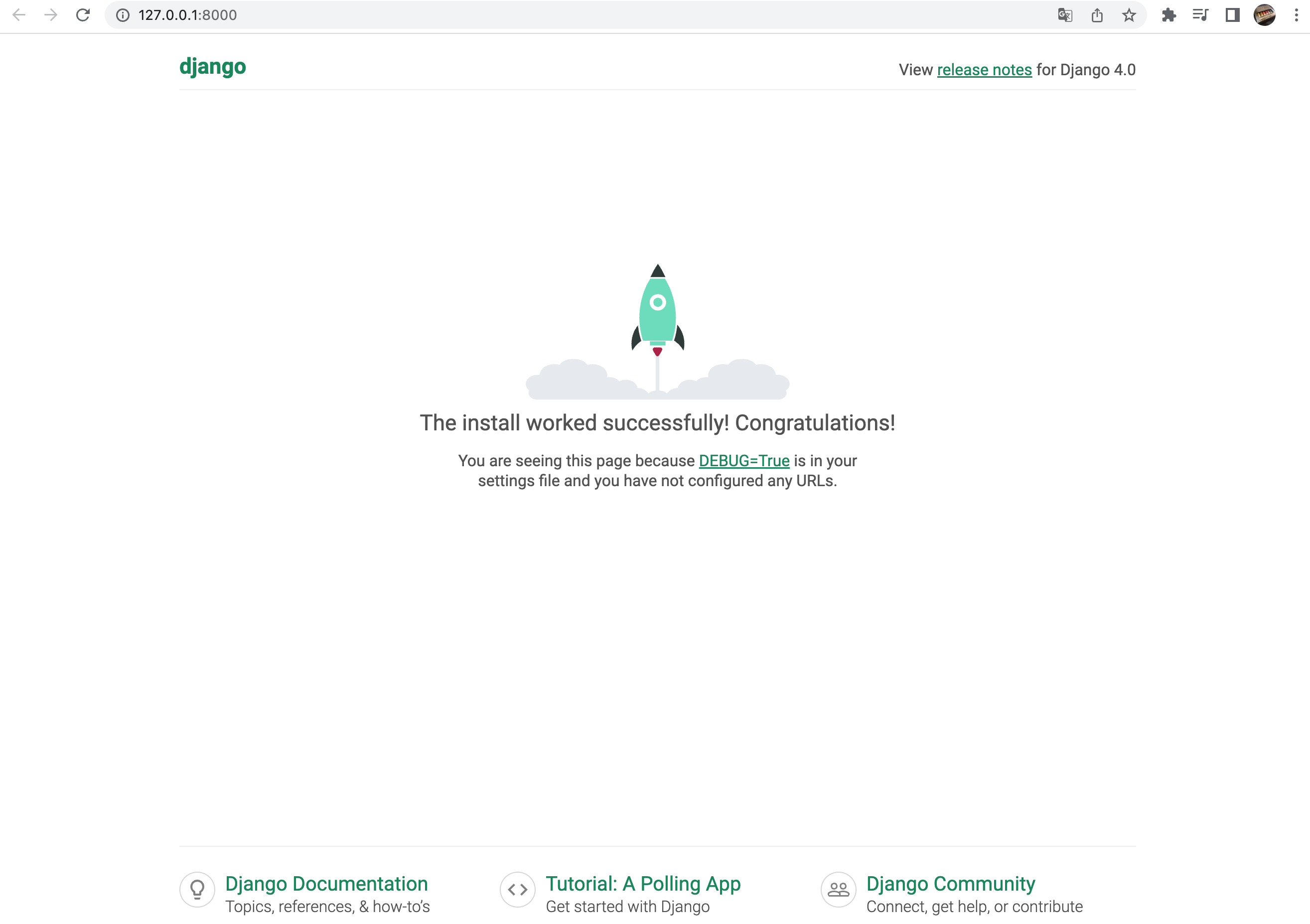
1. aws에서 Windows 인스턴스를 만들고 고정 IP를 만들어주어 연결해준다.
AWS LightSail(1) - 인스턴스 생성하기
정말 빠르게 AWS LightSail로 인스턴스를 만들어보자. Lightsail에 관하여 https://lightsail.aws.amazon.com/ls/docs/ko_kr/all 1. aws 사이트에 회원가입, 로그인을 하고 Lightsail 서버를 찾아서 들어간다. 2...
typo.tistory.com
2. 맥북 환경이면 Microsoft Remote Desktop 앱을 깔아서 아이디와 비밀번호 연결 후 접속해준다.
인스턴스 초기 아이디 비밀번호는 aws 에서 확인하실 수 있습니다.
( aws 에서 RDP로 접속하니 좀 느렸습니다. )
3. aws 에서는 윈도우 서버를 만들고 파일을 다운받으려 할 때 에러가 뜬다. 아래처럼 해주자.
- EC2 Windows 인스턴스에 연결합니다.
- Windows 시작 메뉴를 열고 서버 관리자를 엽니다.
- EC2 Windows 인스턴스에서 실행 중인 Windows Server 버전에 대한 지침을 따릅니다.
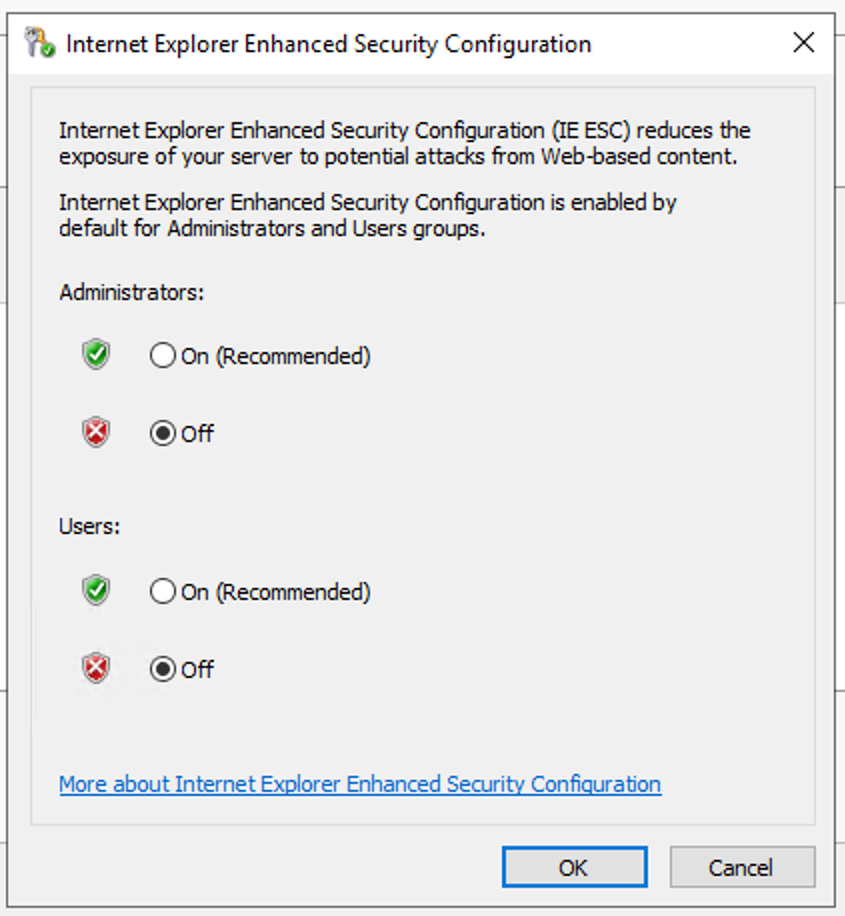
Windows Server 2012 R2, Windows Server 2016 또는 Windows Server 2019: 탐색 창에서 [Server Manager]를 선택합니다. [로컬 서버]를 선택합니다. [IE 보안 강화 구성]에서 [켜기]를 선택합니다.
Windows Server 2008 R2: 탐색 창에서 [Server Manager]를 선택합니다. [서버 요약 - 보안 정보] 섹션에서 [IE ESC 구성]을 선택합니다. - [관리자]에 대해 [끄기]를 선택합니다.
[사용자]에 대해 [끄기]를 선택합니다.
[확인]을 선택합니다. - 서버 관리자를 닫습니다.
Internet Explorer를 사용하여 파일을 다운로드할 수 있도록 EC2 Windows 인스턴스 구성
인터넷에서 Amazon Elastic Compute Cloud(Amazon EC2) Windows 인스턴스에 타사 소프트웨어를 다운로드해야 합니다. Internet Explorer 보안 구성이 내 시도를 차단하고 있습니다. 다운로드를 활성화하려면 어떻
aws.amazon.com
4. Chrome 을 다운로드한다.
https://www.google.com/chrome/index.html
Chrome 웹브라우저
더욱 스마트해진 Google로 더 간편하고 안전하고 빠르게.
www.google.com
5. 아래 사진처럼 크롬 버전을 익혀둔다.
6. 크롬 버전을 확인했으면 앞자리 수에 맞는 크롬 드라이버를 설치한다.
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 104, please download ChromeDriver 104.0.5112.29 If you are using Chrome version 103, please download ChromeDriver 103.0.5060.53 If you are using Chrome version 102, please download ChromeDriver 102.0.5005.61
chromedriver.chromium.org
7. 윈도우로 설치해준다. ( 버전은 다를 수 있습니다. )
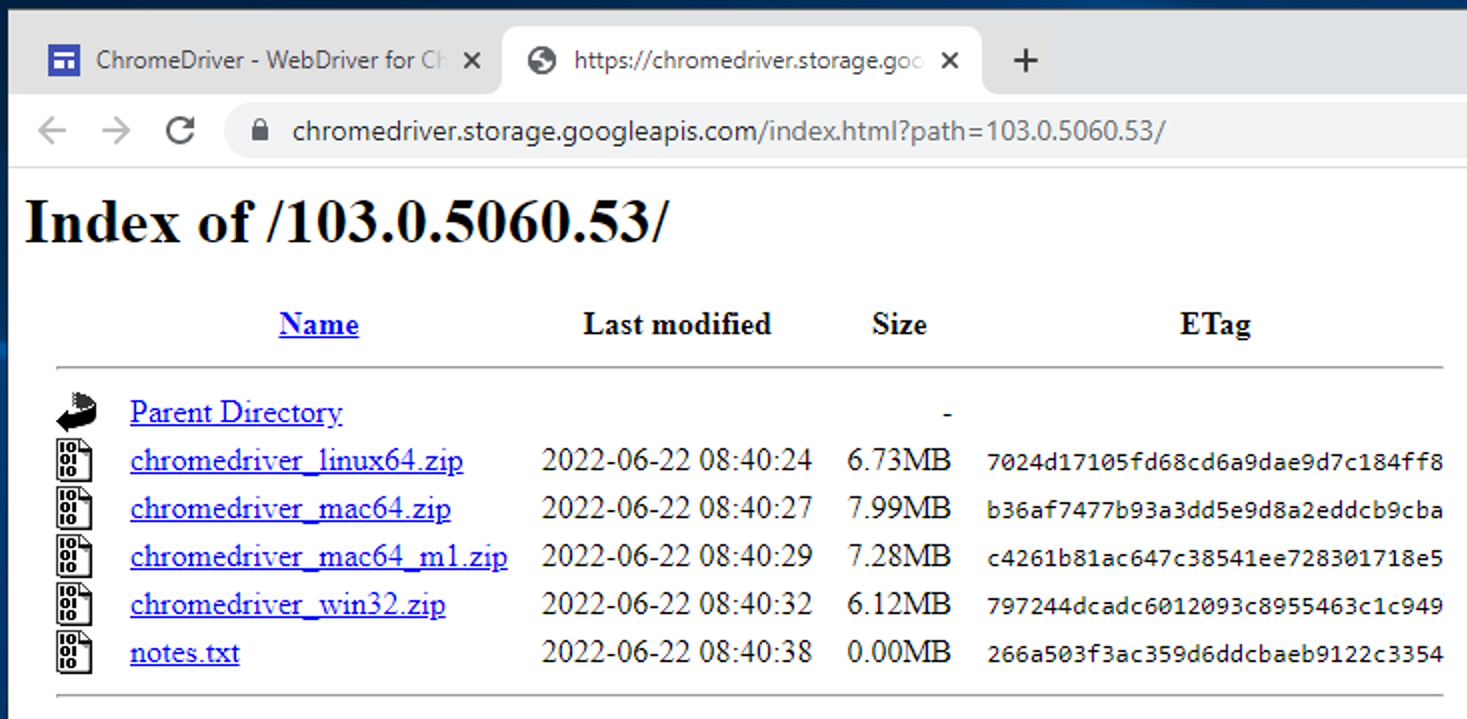
8. 압축을 해제한 후 해당 파일 경로를 알아둔다. ( 나중에 셀레니움에서 사용 )
9. 개발환경을 위해 Vscode와 파이썬을 설치해준다.
Visual Studio Code - Code Editing. Redefined
Visual Studio Code is a code editor redefined and optimized for building and debugging modern web and cloud applications. Visual Studio Code is free and available on your favorite platform - Linux, macOS, and Windows.
code.visualstudio.com
Download Python
The official home of the Python Programming Language
www.python.org
파이썬을 설치할 때 환경변수를 지정해두면 좋다.
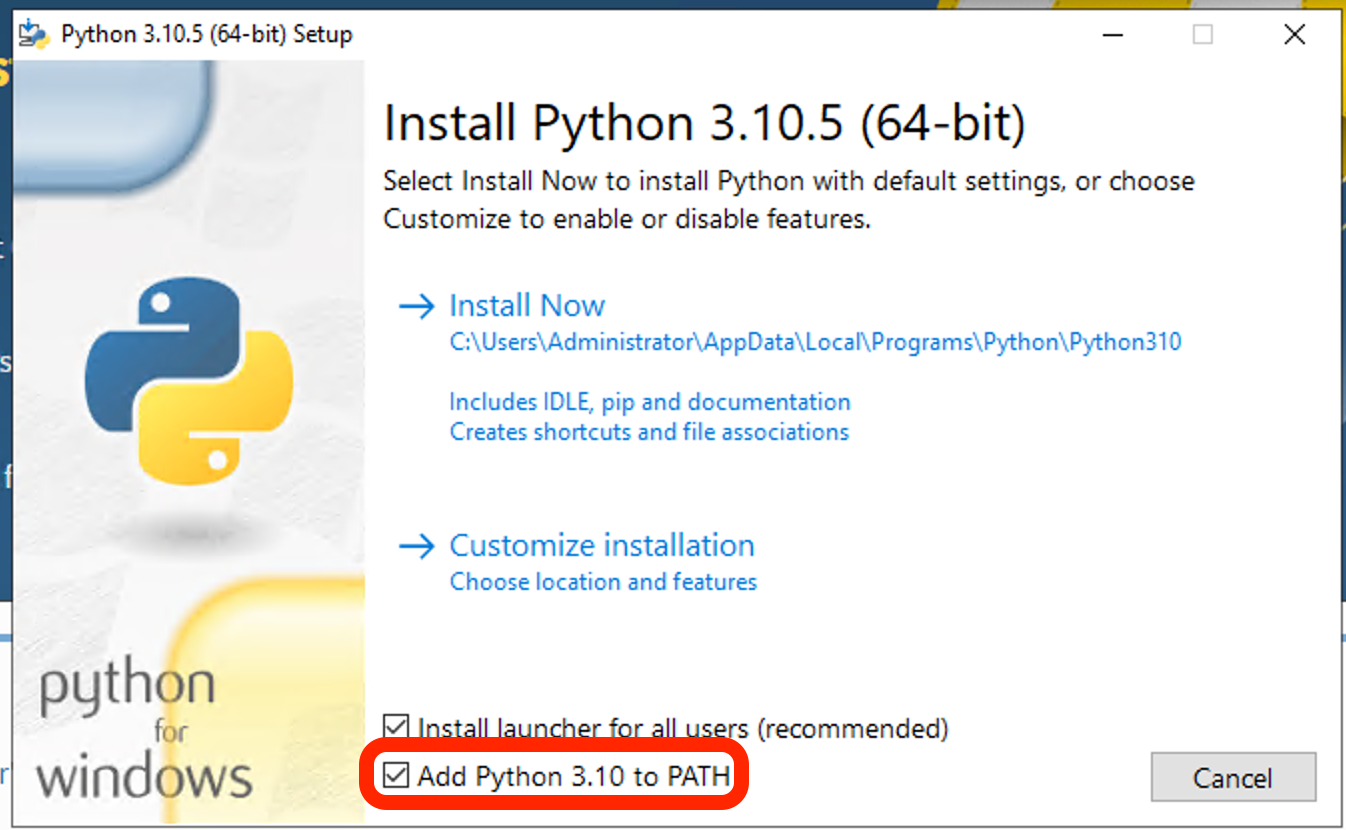
10. 작업하길 원하는 위치에 폴더를 만들고 가상환경을 만들어준다.
$ python -m venv example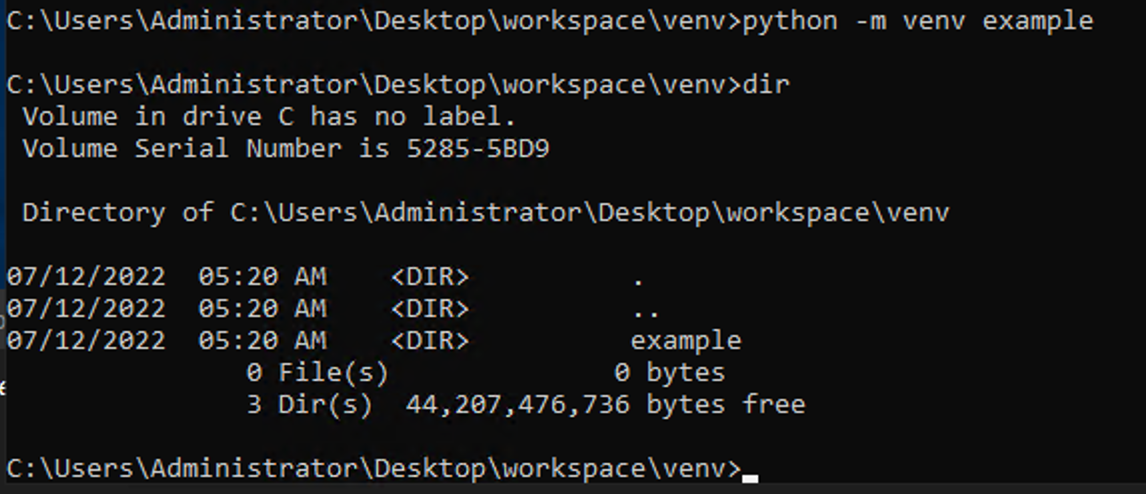
11. django와 djangorestframework를 설치해준다.
$ pip install django
$ pip install djangorestframework markdown
$ django-admin startproject apiServer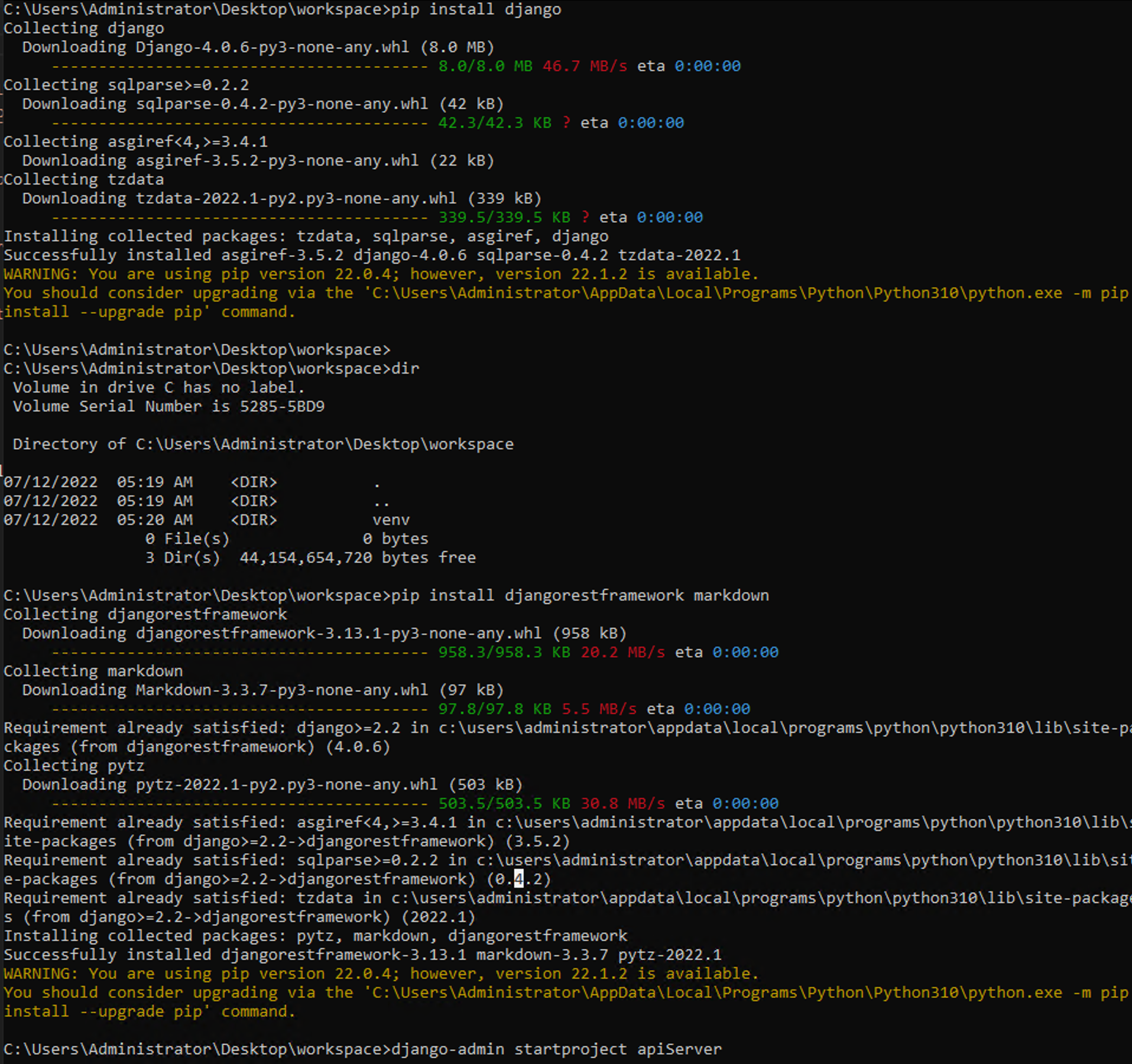
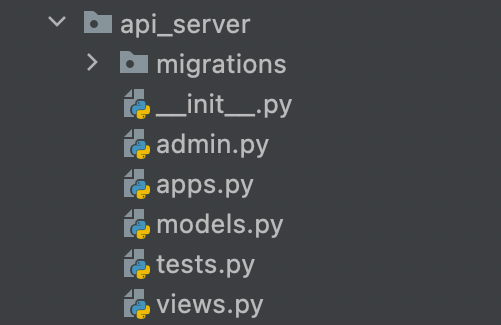
12. VSCode 에서 보면 파일 구조는 이럴 것이다.
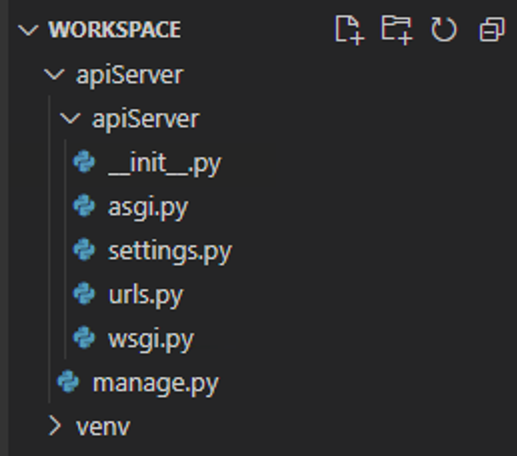
참고로 아래 확장 설치하시면 편합니다